so don’t use 90B’s ea_non_iid at all. De-correlate instead.
This page’s analysis of ea_non_iid pertains to v1.0 of the NIST SP 800-90B suite released 21 May 2019, located here at GitHub. We are mainly looking at non IID entropy measurement of four widely different correlated sample distributions, and one perfectly uniform IID distribution just for fun. The previous analyses were carried out on a much earlier codebase. It seems to have improved a small little, but still remains pretty much useless.
Perfect IID uniform distribution
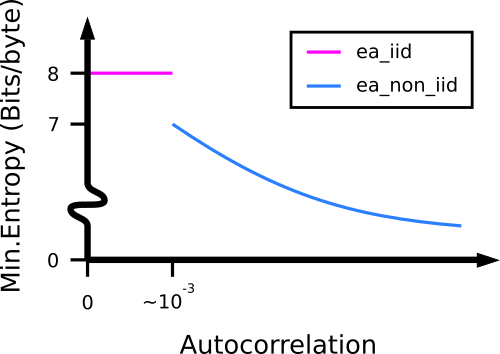
Why? Because we immediately see a problem with the non_IID test. Assume a perfectly random and IID 1 MB file created as dd if=/dev/urandom of=/tmp/urandom bs=1000 count=1000. Theoretically $H_{\infty} = 8$ bits/byte. From ent we measure normalised autocorrelation ($R$) to be -0.002010. As can be seen from the ea_iid test output below, NIST considers the file to be independent and identically distributed. Yet if $R=-0.002010$ and not zero, we are justified in running ea_non_iid and expect $H_{\infty} \approx 8$ bits/byte. The anecdotal normalised threshold for an IID determination is at $R \approx 10^{-3}$.
Yet from ea_non_iid below we have $ H_{\infty} = 7.048241$ bits/byte. Nearly an entire bit of entropy has disappeared when the non-IID test is run. That’s a 12% entropy loss in just using an alternative set of algorithms. Entropy and autocorrelation are linear properties, and we expect the measurement of a sample’s min.entropy to also decrease continuously and smoothly as autocorrelation increases from the ideal $R=0$. There should not be a discontinuity in $H_{\infty}$ between ea_iid and ea_non_iid programs as charted below:-
Expand NIST IID, non-IID and ent tests over a perfectly random file:-
$ /nist-iid-tests/cpp/ea_iid -v /tmp/urandom
Opening file: '/tmp/urandom'
Loaded 1000000 samples of 256 distinct 8-bit-wide symbols
Number of Binary samples: 8000000
Calculating baseline statistics...
Raw Mean: 127.458169
Median: 127.000000
Binary: false
Literal MCV Estimate: mode = 4055, p-hat = 0.0040549999999999996, p_u = 0.0042186931114674428
Bitstring MCV Estimate: mode = 4000638, p-hat = 0.50007975000000005, p_u = 0.50053509661459672
H_original: 7.888988
H_bitstring: 0.998457
min(H_original, 8 X H_bitstring): 7.888988 <====
Chi square independence
score = 65202.390338
degrees of freedom = 65280
p-value = 0.584348
Chi square goodness of fit
score = 2272.595649
degrees of freedom = 2295
p-value = 0.626246
** Passed chi square tests
LiteralLongest Repeated Substring results
P_col: 0.00390728
Length of LRS: 5
Pr(X >= 1): 0.365769
** Passed length of longest repeated substring test
Beginning initial tests...
Initial test results
excursion: 101647
numDirectionalRuns: 667282
lenDirectionalRuns: 9
numIncreasesDecreases: 501900
numRunsMedian: 500737
lenRunsMedian: 19
avgCollision: 19.7822
maxCollision: 71
periodicity(1): 3850
periodicity(2): 3873
periodicity(8): 3869
periodicity(16): 3900
periodicity(32): 3922
covariance(1): 1.62346e+10
covariance(2): 1.62496e+10
covariance(8): 1.62464e+10
covariance(16): 1.6242e+10
covariance(32): 1.62475e+10
compression: 1.06777e+06
Beginning permutation tests... these may take some time
83.83% of Permutuation test rounds, 100.00% of Permutuation tests
statistic C[i][0] C[i][1] C[i][2]
----------------------------------------------------
excursion 6 0 167
numDirectionalRuns 6 0 84
lenDirectionalRuns 2 4 16
numIncreasesDecreases 13 0 6
numRunsMedian 6 0 92
lenRunsMedian 5 3 3
avgCollision 6 0 58
maxCollision 9 1 5
periodicity(1) 22 1 5
periodicity(2) 13 0 6
periodicity(8) 16 0 6
periodicity(16) 7 0 6
periodicity(32) 6 0 14
covariance(1) 313 0 6
covariance(2) 7 0 6
covariance(8) 6 0 11
covariance(16) 6 0 6
covariance(32) 6 0 26
compression 6 0 16
(* denotes failed test)
** Passed IID permutation tests <====
$ /nist-iid-tests/cpp/ea_non_iid -v /tmp/urandom
Opening file: '/tmp/urandom'
Loaded 1000000 samples of 256 distinct 8-bit-wide symbols
Number of Binary Symbols: 8000000
Running non-IID tests...
Running Most Common Value Estimate...
Bitstring MCV Estimate: mode = 4000638, p-hat = 0.50007975000000005, p_u = 0.50053509661459672
Most Common Value Estimate (bit string) = 0.998457 / 1 bit(s)
Literal MCV Estimate: mode = 4055, p-hat = 0.0040549999999999996, p_u = 0.0042186931114674428
Most Common Value Estimate = 7.888988 / 8 bit(s)
Running Entropic Statistic Estimates (bit strings only)...
Bitstring Collision Estimate: X-bar = 2.4999285957805575, sigma-hat = 0.50000007302423333, p = 0.51989171015067059
Collision Test Estimate (bit string) = 0.943717 / 1 bit(s)
Bitstring Markov Estimate: P_0 = 0.49992025000000001, P_1 = 0.50007975000000005, P_0,0 = 0.49982622228245405, P_0,1 = 0.5001737777175459, P_1,0 = 0.50001437271114579, P_1,1 = 0.49998562728885421, p_max = 3.0097916925051501e-39
Markov Test Estimate (bit string) = 0.999731 / 1 bit(s)
Bitstring Compression Estimate: X-bar = 5.2162477349352701, sigma-hat = 1.0157740570648277, p = 0.025627187992802503
Compression Test Estimate (bit string) = 0.881030 / 1 bit(s)
Running Tuple Estimates...
Bitstring t-Tuple Estimate: t = 19, p-hat_max = 0.5231065809785963, p_u = 0.52356144110715352
Bitstring LRS Estimate: u = 20, v = 44, p-hat = 0.50079312185691827, p_u = 0.50124846790444211
T-Tuple Test Estimate (bit string) = 0.933569 / 1 bit(s)
Literal t-Tuple Estimate: t = 1, p-hat_max = 0.0040549999999999996, p_u = 0.0042186931114674428
Literal LRS Estimate: u = 2, v = 5, p-hat = 0.0045730587507903549, p_u = 0.0047468489906174289
T-Tuple Test Estimate = 7.888988 / 8 bit(s)
LRS Test Estimate (bit string) = 0.996402 / 1 bit(s)
LRS Test Estimate = 7.718814 / 8 bit(s)
Running Predictor Estimates...
Bitstring MultiMCW Prediction Estimate: N = 7999937, Pglobal' = 0.50041541059736405 (C = 3999649) Plocal can't affect result (r = 27)
Multi Most Common in Window (MultiMCW) Prediction Test Estimate (bit string) = 0.998802 / 1 bit(s)
Literal MultiMCW Prediction Estimate: N = 999937, Pglobal' = 0.0041240724521602991 (C = 3962) Plocal can't affect result (r = 3)
Multi Most Common in Window (MultiMCW) Prediction Test Estimate = 7.921715 / 8 bit(s)
Bitstring Lag Prediction Estimate: N = 7999999, Pglobal' = 0.50041465914225436 (C = 3999674) Plocal can't affect result (r = 22)
Lag Prediction Test Estimate (bit string) = 0.998804 / 1 bit(s)
Literal Lag Prediction Estimate: N = 999999, Pglobal' = 0.0040574891226150241 (C = 3897) Plocal can't affect result (r = 3)
Lag Prediction Test Estimate = 7.945197 / 8 bit(s)
Bitstring MultiMMC Prediction Estimate: N = 7999998, Pglobal' = 0.50031084662216663 (C = 3998843) Plocal can't affect result (r = 25)
Multi Markov Model with Counting (MultiMMC) Prediction Test Estimate (bit string) = 0.999103 / 1 bit(s)
Literal MultiMMC Prediction Estimate: N = 999998, Pglobal' = 0.0039513453033008716 (C = 3793) Plocal can't affect result (r = 3)
Multi Markov Model with Counting (MultiMMC) Prediction Test Estimate = 7.983440 / 8 bit(s)
Bitstring LZ78Y Prediction Estimate: N = 7999983, Pglobal' = 0.50017178392839667 (C = 3997723) Plocal can't affect result (r = 21)
LZ78Y Prediction Test Estimate (bit string) = 0.999504 / 1 bit(s)
Literal LZ78Y Prediction Estimate: N = 999983, Pglobal' = 0.003951404569967603 (C = 3793) Plocal can't affect result (r = 3)
LZ78Y Prediction Test Estimate = 7.983419 / 8 bit(s)
H_original: 7.718814
H_bitstring: 0.881030
min(H_original, 8 X H_bitstring): 7.048241 <====
$ ent urandom
Entropy = 7.999810 bits per byte.
Optimum compression would reduce the size
of this 1000000 byte file by 0 percent.
Chi square distribution for 1000000 samples is 262.90, and randomly
would exceed this value 35.36 percent of the times.
Arithmetic mean value of data bytes is 127.4582 (127.5 = random).
Monte Carlo value for Pi is 3.143580574 (error 0.06 percent).
Serial correlation coefficient is -0.002010 (totally uncorrelated = 0.0).
Discontinuity in entropy measurement between ea_iid and ea_non_iid.
Non IID Gaussian distribution
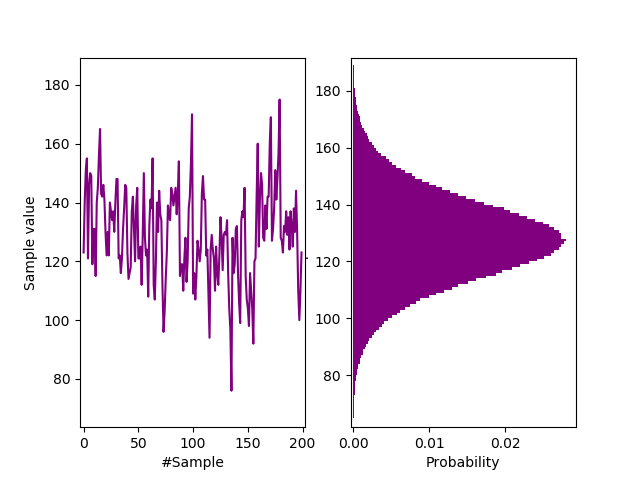
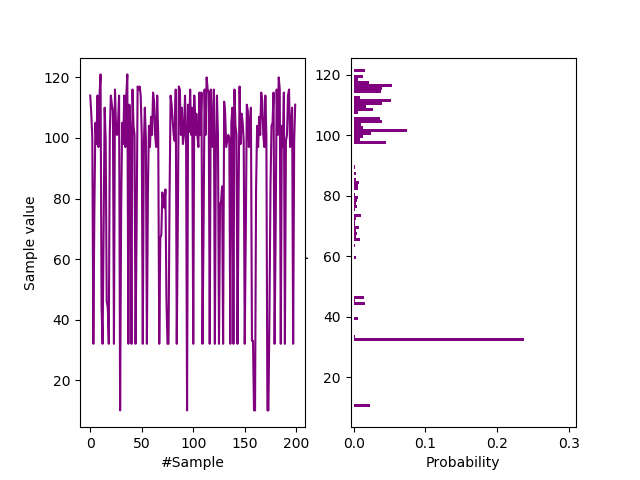
A synthetic Gaussian $\big( N(127, 10) \big)$ data file was generated with strong autocorrelation. This is the most common frequency distribution for analogue entropy sources. See it’s similarity to the Zener distribution of our uber simple Quantum entropy source on a breadboard and our Zenerglass. The Python code creating the simple autoregressive model of order $p=3$ with $\varphi = 1$ is:-
import random
MEAN =127STDEV =10VARPHI =1with open('/tmp/non_iid_gaussian.bin', 'wb') as f:
for i in range(250_000):
value1 = round(random.gauss(MEAN, STDEV))
f.write(value1.to_bytes(1, byteorder='big'))
value2 = round(VARPHI * random.gauss(value1, STDEV))
f.write(value2.to_bytes(1, byteorder='big'))
value3 = round(VARPHI * random.gauss(value2, STDEV))
f.write(value3.to_bytes(1, byteorder='big'))
value4 = round(VARPHI * random.gauss(value3, STDEV))
f.write(value4.to_bytes(1, byteorder='big'))
Frequency distribution.
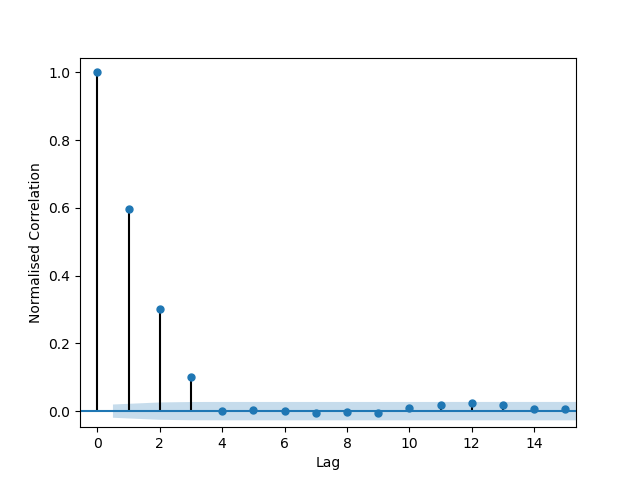
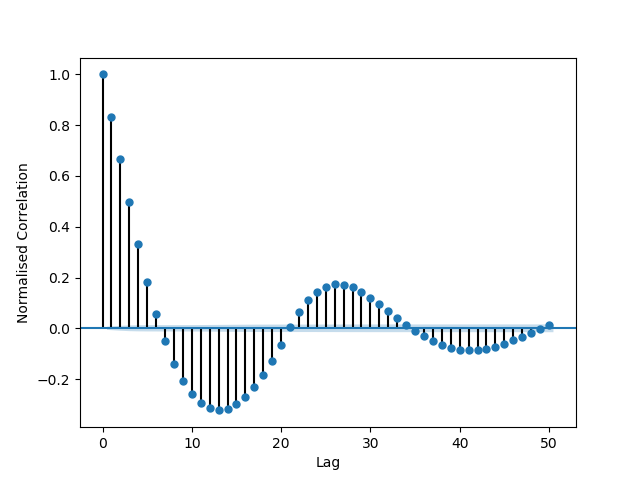
Notice subsequent samples being constructed around the mean of the previous one. Consequently we have a lag of n = 3 giving a maximum autocorrelation coefficient at n = 1 of 0.60 as:-
Autocorrelation with correlation lag of 3.
Pretty correlated then[†].
Expand NIST ea_non_iid test over the non IID Gaussian sample file:-
$ ./ea_non_iid -v /tmp/non_iid_gaussian.bin
Opening file: '/tmp/non_iid_gaussian.bin'
Loaded 1000000 samples of 173 distinct 8-bit-wide symbols
Number of Binary Symbols: 8000000
Symbols have been translated.
Running non-IID tests...
Running Most Common Value Estimate...
Bitstring MCV Estimate: mode = 4016551, p-hat = 0.50206887499999997, p_u = 0.50252421772238298
Most Common Value Estimate (bit string) = 0.992735 / 1 bit(s)
Literal MCV Estimate: mode = 27959, p-hat = 0.027959000000000001, p_u = 0.028383639515378402
Most Common Value Estimate = 5.138797 / 8 bit(s)
Running Entropic Statistic Estimates (bit strings only)...
Bitstring Collision Estimate: X-bar = 2.502088149202037, sigma-hat = 0.49999571780349805, p = 0.5
Collision Test Estimate (bit string) = 1.000000 / 1 bit(s)
Bitstring Markov Estimate: P_0 = 0.49793112499999997, P_1 = 0.50206887499999997, P_0,0 = 0.5225382633336747, P_0,1 = 0.4774617366663253, P_1,0 = 0.47352666504172358, P_1,1 = 0.52647333495827642, p_max = 2.0680618683727687e-36
Markov Test Estimate (bit string) = 0.926103 / 1 bit(s)
Bitstring Compression Estimate: X-bar = 5.0296231457661316, sigma-hat = 1.0343636082033609, p = 0.11903292748584995
Compression Test Estimate (bit string) = 0.511761 / 1 bit(s)
Running Tuple Estimates...
Bitstring t-Tuple Estimate: t = 28, p-hat_max = 0.64607786215956309, p_u = 0.64651334235348301
Bitstring LRS Estimate: u = 29, v = 57, p-hat = 0.60422001636666878, p_u = 0.6046653613664047
T-Tuple Test Estimate (bit string) = 0.629248 / 1 bit(s)
Literal t-Tuple Estimate: t = 3, p-hat_max = 0.040000026666702229, p_u = 0.040504784476979597
Literal LRS Estimate: u = 4, v = 7, p-hat = 0.02493902993999126, p_u = 0.025340703237318067
T-Tuple Test Estimate = 4.625764 / 8 bit(s)
LRS Test Estimate (bit string) = 0.725791 / 1 bit(s)
LRS Test Estimate = 5.302400 / 8 bit(s)
Running Predictor Estimates...
Bitstring MultiMCW Prediction Estimate: N = 7999937, Pglobal' = 0.50588692681874214 (C = 4043421) Plocal can't affect result (r = 9)
Multi Most Common in Window (MultiMCW) Prediction Test Estimate (bit string) = 0.983113 / 1 bit(s)
Literal MultiMCW Prediction Estimate: N = 999937, Pglobal' = 0.027373884929103202 (C = 26955) Plocal can't affect result (r = 5)
Multi Most Common in Window (MultiMCW) Prediction Test Estimate = 5.191056 / 8 bit(s)
Bitstring Lag Prediction Estimate: N = 7999999, Pglobal' = 0.58472902927774673 (C = 4674241) Plocal can't affect result (r = 33)
Lag Prediction Test Estimate (bit string) = 0.774160 / 1 bit(s)
Literal Lag Prediction Estimate: N = 999999, Pglobal' = 0.034789970870550399 (C = 34321) Plocal can't affect result (r = 5)
Lag Prediction Test Estimate = 4.845185 / 8 bit(s)
Bitstring MultiMMC Prediction Estimate: N = 7999998, Pglobal' = 0.69220256709424288 (C = 5534255) Plocal can't affect result (r = 34)
Multi Markov Model with Counting (MultiMMC) Prediction Test Estimate (bit string) = 0.530734 / 1 bit(s)
Literal MultiMMC Prediction Estimate: N = 999998, Pglobal' = 0.034330989065283812 (C = 33865) Plocal can't affect result (r = 5)
Multi Markov Model with Counting (MultiMMC) Prediction Test Estimate = 4.864345 / 8 bit(s)
Bitstring LZ78Y Prediction Estimate: N = 7999983, Pglobal' = 0.52496791413576094 (C = 4196096) Plocal can't affect result (r = 8)
LZ78Y Prediction Test Estimate (bit string) = 0.929699 / 1 bit(s)
Literal LZ78Y Prediction Estimate: N = 999983, Pglobal' = 0.034258017806344403 (C = 33792) Plocal can't affect result (r = 5)
LZ78Y Prediction Test Estimate = 4.867415 / 8 bit(s)
H_original: 4.625764
H_bitstring: 0.511761
min(H_original, 8 X H_bitstring): 4.094090
The test gives $H_{\infty}=4.094$ bits/byte. Not unreasonable. But this happens to be $8 \times \text{H_bitstring}$ and ironically $\text{H_bitstring}$ is calculated via a (weakly implemented) compression test. The test is based on the Maurer Universal Statistic modified to calculate min.entropy rather than Shannon entropy (ref. 800-90B §6.3.4):-
Compression Test Estimate (bit string) = 0.511761 / 1 bit(s)
Comparing $H_{\infty}=4.094$ bits/byte with a Shannon entropy value obtained via strong compression:-
$ ./cmix_v17 -c /tmp/non_iid_gaussian.bin non_iid_gaussian.cmix
1000000 bytes -> 675105 bytes in 1438.83 s.
cross entropy: 5.401
This seems sane, but we are left wondering as to the relationship between min.entropy and Shannon entropy in the general case. We will always be wondering how much further might strong compression go? Even worse is that the NIST Compression Test Estimate is based on a weak algorithm that executes within seconds. Based on past experience of myriad empirical distributions, we believe $\frac{H_{Compression}}{H_{\infty}} \ngtr 2$ in most cases. If we hold to compressive entropy measurement and our conservative ratio of two, we arrive at $H_{\infty | Compression} = 2.7005$ bits/byte for this Gaussian non-IID file.
Non IID binary distribution
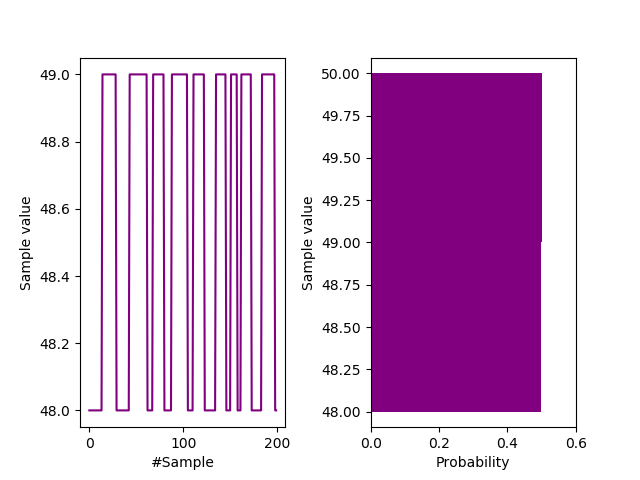
By binary, we mean an entropy source that produces only two possible outputs, as $ X_i \in \{ 0, 1 \}^{5 \rightarrow 20} $ as text or $ X_i \in \{ 48, 49 \}^{5 \rightarrow 20} $ as ASCII binary, creating a relaxation period of 5.
Such a format is common in thresholded sampling and oversampled sources like our example Zener signal. Unbiased but highly correlated as results from an over zealous $(\epsilon, \tau)$ sampling regime where $\tau$ is too short an interval. Created like this:-
import random
MIN =5MAX =20with open('/tmp/non_iid.txt', 'w') as f:
for i in range(100_000):
zeros = random.randint(MIN, MAX)
for z in range(zeros):
f.write("0")
ones = random.randint(MIN, MAX)
for o in range(ones):
f.write("1")
Frequency distribution.
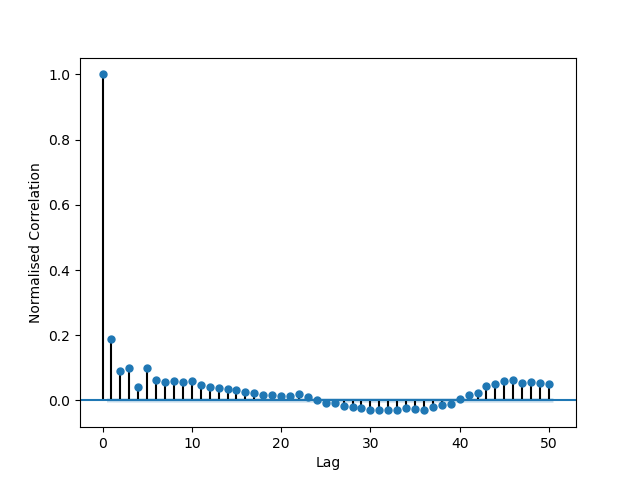
Autocorrelation with lags of 4 to 19.
Expand NIST ea_non_iid test over a non-IID binary file:-
$ ea_non_iid -v /tmp/non_iid.txt
Opening file: '/tmp/non_iid.txt'
Loaded 2399253 samples of 2 distinct 6-bit-wide symbols
Symbols have been translated.
Running non-IID tests...
Running Most Common Value Estimate...
Literal MCV Estimate: mode = 1202339, p-hat = 0.50113056022020186, p_u = 0.5019620330092206
Most Common Value Estimate = 0.994350 / 6 bit(s)
Running Entropic Statistic Estimates (bit strings only)...
Literal Collision Estimate: X-bar = 2.0814291725044352, sigma-hat = 0.27349319417456697, p = 0.95783565961423456
Collision Test Estimate = 0.062150 / 1 bit(s)
Literal Markov Estimate: P_0 = 0.49886943977979814, P_1 = 0.50113056022020186, P_0,0 = 0.91645180856769992, P_0,1 = 0.083548191432300078, P_1,0 = 0.083170456227782866, P_1,1 = 0.91682954377221715, p_max = 8.1395992428504138e-06
Markov Test Estimate = 0.132083 / 1 bit(s)
Literal Compression Estimate: X-bar = 2.4693381638872132, sigma-hat = 1.0926021040767067, p = 0.67745583124958442
Compression Test Estimate = 0.093634 / 1 bit(s)
Running Tuple Estimates...
Literal t-Tuple Estimate: t = 72, p-hat_max = 0.85817792191411202, p_u = 0.85875807116775971
Literal LRS Estimate: u = 73, v = 134, p-hat = 0.81559070880891404, p_u = 0.81623563004980648
T-Tuple Test Estimate = 0.219676 / 6 bit(s)
LRS Test Estimate = 0.292942 / 6 bit(s)
Running Predictor Estimates...
Literal MultiMCW Prediction Estimate: N = 2399190, Pglobal' = 0.51857194984164823 (C = 1242159) Plocal can't affect result (r = 21)
Multi Most Common in Window (MultiMCW) Prediction Test Estimate = 0.947384 / 6 bit(s)
Literal Lag Prediction Estimate: N = 2399252, Pglobal' = 0.91710078237306125 (C = 2199253) Plocal can't affect result (r = 20)
Lag Prediction Test Estimate = 0.124848 / 6 bit(s)
Literal MultiMMC Prediction Estimate: N = 2399251, Pglobal' = 0.91710033206017816 (C = 2199251) Plocal can't affect result (r = 20)
Multi Markov Model with Counting (MultiMMC) Prediction Test Estimate = 0.124849 / 6 bit(s)
Literal LZ78Y Prediction Estimate: N = 2399236, Pglobal' = 0.91710064515088008 (C = 2199238) Plocal can't affect result (r = 20)
LZ78Y Prediction Test Estimate = 0.124848 / 6 bit(s)
H_original: 0.062150
Collision Test Estimate = 0.062150 / 1 bit(s)
which is also 0.062150 bits/character given the file is in octets.
~/cmix_v17 -c /tmp/non_iid.txt non_iid_txt.cmix
2399253 bytes -> 103019 bytes in 2128.56 s.
cross entropy: 0.344
Knowing the generating algorithm, we can deduce that the expectation $E(X) = \frac{5 + 20}{2} = 12.5$. Therefore is $H_{\infty} = \frac{1}{12.5} = 0.08$ bits/byte which seemingly matches the above 90B result, given that the expectation of a uniform distribution $U(a, b)$ is $\frac{a + b}{2}$ and allowing for some random quantum fluctuations?
Make of this what you will. $\frac{H_{Compression|cmix}}{H_{\infty}} = 5.5$, but we have no other way to verify this.
“Can you show a sample that fools NIST SP 800-90B? NIST SP 800-90B has been reported to give ‘massive underestimates’?”
Yes, very much so. We have an intractably correlated ASCII text file in the following format of Shakespeare’s complete works (~5.4 MB) as:-
Chor. Two households, both alike in dignity,
In fair Verona, where we lay our scene,
From ancient grudge break to new mutiny,
Where civil blood makes civil hands unclean.
From forth the fatal loins of these two foes
A pair of star-cross'd lovers take their life;
Whose misadventur'd piteous overthrows
Doth with their death bury their parents' strife.
The fearful passage of their death-mark'd love,
And the continuance of their parents' rage,
Which, but their children's end, naught could remove,
Is now the two hours' traffic of our stage;
The which if you with patient ears attend,
What here shall miss, our toil shall strive to mend...
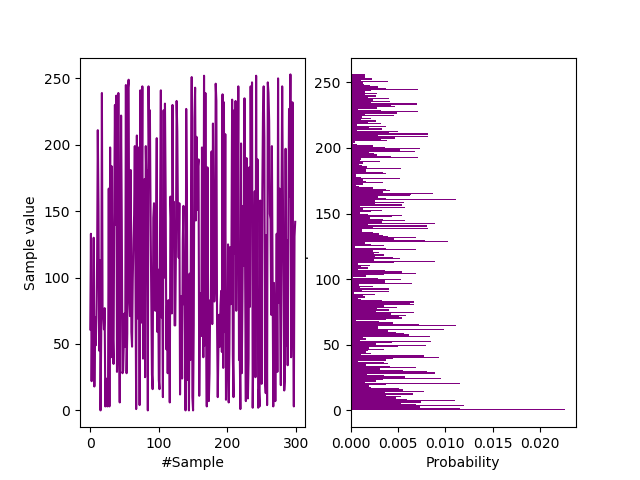
ASCII frequency distribution.
Autocorrelation.
Expand NIST ea_non_iid test over Shakespeare’s complete works:-
$ ./ea_non_iid -v /tmp/shakespeare.txt
Opening file: '/tmp/shakespeare.txt'
Loaded 5458199 samples of 91 distinct 7-bit-wide symbols
Number of Binary Symbols: 38207393
Symbols have been translated.
Running non-IID tests...
Running Most Common Value Estimate...
Bitstring MCV Estimate: mode = 20091933, p-hat = 0.52586505967575436, p_u = 0.52607314024188456
Most Common Value Estimate (bit string) = 0.926665 / 1 bit(s)
Literal MCV Estimate: mode = 1293934, p-hat = 0.23706244495666062, p_u = 0.23753133208712304
Most Common Value Estimate = 2.073810 / 7 bit(s)
Running Entropic Statistic Estimates (bit strings only)...
Bitstring Collision Estimate: X-bar = 2.4404964312409465, sigma-hat = 0.49644671521475731, p = 0.67295484479163759
Collision Test Estimate (bit string) = 0.571418 / 1 bit(s)
Bitstring Markov Estimate: P_0 = 0.52586505967575436, P_1 = 0.47413494032424564, P_0,0 = 0.55183742409639847, P_0,1 = 0.44816257590360153, P_1,0 = 0.49705903134670609, P_1,1 = 0.50294096865329396, p_max = 8.5288473260673173e-34
Markov Test Estimate (bit string) = 0.858228 / 1 bit(s)
Bitstring Compression Estimate: X-bar = 5.0931473909524403, sigma-hat = 1.0676109266197478, p = 0.094486545727304694
Compression Test Estimate (bit string) = 0.567291 / 1 bit(s)
Running Tuple Estimates...
Bitstring t-Tuple Estimate: t = 3741, p-hat_max = 0.99659310947332325, p_u = 0.99661739130319049
Bitstring LRS Estimate: u = 3742, v = 4152, p-hat = 0.99391121697095386, p_u = 0.99394363468803215
T-Tuple Test Estimate (bit string) = 0.004888 / 1 bit(s)
Literal t-Tuple Estimate: t = 534, p-hat_max = 0.98015625276411322, p_u = 0.98031001579721644
Literal LRS Estimate: u = 535, v = 593, p-hat = 0.96168629234477643, p_u = 0.96189792673443286
T-Tuple Test Estimate = 0.028690 / 7 bit(s)
LRS Test Estimate (bit string) = 0.008764 / 1 bit(s)
LRS Test Estimate = 0.056044 / 7 bit(s)
Running Predictor Estimates...
Bitstring MultiMCW Prediction Estimate: N = 38207330, Pglobal' = 0.52560879257822302 (C = 20074158) Plocal can't affect result (r = 9)
Multi Most Common in Window (MultiMCW) Prediction Test Estimate (bit string) = 0.927939 / 1 bit(s)
Literal MultiMCW Prediction Estimate: N = 5458136, Pglobal' = 0.23752545606020314 (C = 1293887) Plocal = 0.72695387687625701 (r = 59)
Multi Most Common in Window (MultiMCW) Prediction Test Estimate = 0.460064 / 7 bit(s)
Bitstring Lag Prediction Estimate: N = 38207392, Pglobal' = 0.6104897660096964 (C = 23317457) Plocal = 0.95254218653736566 (r = 391)
Lag Prediction Test Estimate (bit string) = 0.070145 / 1 bit(s)
Literal Lag Prediction Estimate: N = 5458198, Pglobal' = 0.094420541102387637 (C = 513609) Plocal = 0.70478303874339931 (r = 54)
Lag Prediction Test Estimate = 0.504749 / 7 bit(s)
Bitstring MultiMMC Prediction Estimate: N = 38207391, Pglobal' = 0.86113192803918903 (C = 32896096) Plocal = 0.955913069685288 (r = 420)
Multi Markov Model with Counting (MultiMMC) Prediction Test Estimate (bit string) = 0.065049 / 1 bit(s)
Literal MultiMMC Prediction Estimate: N = 5458197, Pglobal' = 0.54082550514784433 (C = 2948933) Plocal = 0.74614115811246973 (r = 64)
Multi Markov Model with Counting (MultiMMC) Prediction Test Estimate = 0.422480 / 7 bit(s)
Bitstring LZ78Y Prediction Estimate: N = 38207376, Pglobal' = 0.52886101863123014 (C = 20198444) Plocal can't affect result (r = 9)
LZ78Y Prediction Test Estimate (bit string) = 0.919039 / 1 bit(s)
Literal LZ78Y Prediction Estimate: N = 5458182, Pglobal' = 0.3007894330454387 (C = 1639005) Plocal = 0.73101005218343218 (r = 60)
LZ78Y Prediction Test Estimate = 0.452037 / 7 bit(s)
H_original: 0.028690
H_bitstring: 0.004888
min(H_original, 7 X H_bitstring): 0.028690
which gives:-
min(H_original, 7 X H_bitstring): 0.028690 bits/character.
And now by strong compression (cmix):-
$ ./cmix_v17 -c /tmp/shakespeare.txt shakey.cmix
5458199 bytes -> 1034003 bytes in 6701.17 s.
cross entropy: 1.516
And we know from Shannon’s 1950 work that general English text has an entropy of approximately 0.6 - 1.3 bits/character. Schürmann and Grassberger have the asymptotic entropy of these works as 1.7 bits/character. The current (world class) cmix compression algorithm estimates the entropy of enwik9 to be 0.93 bits/byte.
We can conclude that cmix and other strong compression algorithms are fairly accurate in determining at least Shannon entropy given our current state of knowledge. It certainly appears to be in the order of ~1 bit/character. Therefore it is difficult to accept the 90B $H_{\infty} = 0.028690$ bits/character result given that it would imply $\frac{H_{Compression|cmix}}{H_{\infty}} > 52$! But as highlighted previously, what is it’s exact relationship to min.entropy?
Photonic Instrument JPEGs
Wacky JPEG frequency distribution.
Expand NIST ea_non_iid test over 50 concatenated JPEG frames:-
$ea_non_iid -v /tmp/50-frames.bin
Opening file: '/tmp/50-frames.bin'
Loaded 1077644 samples of 256 distinct 8-bit-wide symbols
Number of Binary Symbols: 8621152
Running non-IID tests...
Running Most Common Value Estimate...
Bitstring MCV Estimate: mode = 4876088, p-hat = 0.56559587396208766, p_u = 0.56603071902214974
Most Common Value Estimate (bit string) = 0.821048 / 1 bit(s)
Literal MCV Estimate: mode = 24426, p-hat = 0.022666112371061316, p_u = 0.023035421141070812
Most Common Value Estimate = 5.440002 / 8 bit(s)
Running Entropic Statistic Estimates (bit strings only)...
Bitstring Collision Estimate: X-bar = 2.4773389693405612, sigma-hat = 0.49948628547827656, p = 0.60805256950524667
Collision Test Estimate (bit string) = 0.717732 / 1 bit(s)
Bitstring Markov Estimate: P_0 = 0.56559587396208766, P_1 = 0.43440412603791234, P_0,0 = 0.59441310214522425, P_0,1 = 0.40558689785477575, P_1,0 = 0.52807588868975275, P_1,1 = 0.47192411131024725, p_max = 1.1527355460690412e-29
Markov Test Estimate (bit string) = 0.751022 / 1 bit(s)
Bitstring Compression Estimate: X-bar = 5.0524400253217756, sigma-hat = 1.085566605167352, p = 0.1107179557136273
Compression Test Estimate (bit string) = 0.529173 / 1 bit(s)
Running Tuple Estimates...
Bitstring t-Tuple Estimate: t = 4892, p-hat_max = 0.99753686156111676, p_u = 0.99758034694827136
Bitstring LRS Estimate: u = 4893, v = 4955, p-hat = 0.99564749486560644, p_u = 0.99570524551902162
T-Tuple Test Estimate (bit string) = 0.003495 / 1 bit(s)
Literal t-Tuple Estimate: t = 611, p-hat_max = 0.98380250129291491, p_u = 0.98411572711780682
Literal LRS Estimate: u = 612, v = 618, p-hat = 0.9689826180374298, p_u = 0.96941278810318132
T-Tuple Test Estimate = 0.023100 / 8 bit(s)
LRS Test Estimate (bit string) = 0.006209 / 1 bit(s)
LRS Test Estimate = 0.044817 / 8 bit(s)
Running Predictor Estimates...
Bitstring MultiMCW Prediction Estimate: N = 8621089, Pglobal' = 0.56583200222940833 (C = 4874339) Plocal = 0.77262981825571408 (r = 74)
Multi Most Common in Window (MultiMCW) Prediction Test Estimate (bit string) = 0.372151 / 1 bit(s)
Literal MultiMCW Prediction Estimate: N = 1077581, Pglobal' = 0.022914230244823291 (C = 24295) Plocal = 0.70809264534296212 (r = 50)
Multi Most Common in Window (MultiMCW) Prediction Test Estimate = 0.497990 / 8 bit(s)
Bitstring Lag Prediction Estimate: N = 8621151, Pglobal' = 0.54427952641116861 (C = 4688549) Plocal = 0.95684011863011209 (r = 395)
Lag Prediction Test Estimate (bit string) = 0.063650 / 1 bit(s)
Literal Lag Prediction Estimate: N = 1077643, Pglobal' = 0.0097626743459977277 (C = 10261) Plocal = 0.70809178896481118 (r = 50)
Lag Prediction Test Estimate = 0.497992 / 8 bit(s)
Bitstring MultiMMC Prediction Estimate: N = 8621150, Pglobal' = 0.70344880838879453 (C = 6061082) Plocal = 0.9568401189277379 (r = 395)
Multi Markov Model with Counting (MultiMMC) Prediction Test Estimate (bit string) = 0.063650 / 1 bit(s)
Literal MultiMMC Prediction Estimate: N = 1077642, Pglobal' = 0.061070743737962487 (C = 65175) Plocal = 0.83405201174240617 (r = 92)
Multi Markov Model with Counting (MultiMMC) Prediction Test Estimate = 0.261791 / 8 bit(s)
Bitstring LZ78Y Prediction Estimate: N = 8621135, Pglobal' = 0.56602997893018769 (C = 4876072) Plocal = 0.77262975986285864 (r = 74)
LZ78Y Prediction Test Estimate (bit string) = 0.372151 / 1 bit(s)
Literal LZ78Y Prediction Estimate: N = 1077627, Pglobal' = 0.051094491145957613 (C = 54475) Plocal = 0.72276621269981756 (r = 53)
LZ78Y Prediction Test Estimate = 0.468399 / 8 bit(s)
H_original: 0.023100
H_bitstring: 0.003495
min(H_original, 8 X H_bitstring): 0.023100
This latest version still gives $H_{\infty} = 0.023$ bits/bytes. Exactly as before. And so, $\frac{H_{Compression|paq8}}{H_{\infty}} = \frac{4.94}{0.023} > 214! $ Does this make any sense? We think not.
Bugs
Simple code and test problems still persist…
Expand NIST ea_iid test over NIST’s version of pi:-
The igamc: UNDERFLOW error (‘incomplete gamma integral’ - a form of arithmetic underflow) is repeatable and inexcusable. But the more worrying fact is that the test data itself is still incorrect. By virtue of being an irrational number, binary expansions of $\pi$ are perfectly pseudo-random and form one of the gold standards for testing test suites. NIST’s version of $\pi$ is proven to be non-IID. How can we have confidence in a test suite that was validated against dodgy test data?
Furthermore, the kind of spelling mistake below only serves to undermine NIST’s quality control. It may seem trivial at first glance, but ‘Permutation’ is an important word when developing a permutation test.
Beginning permutation tests... these may take some time
100.00% of Permutuation test rounds, 31.58% of Permutuation tests
Focus on detail is vital for scientific programming. If you’ve misspelt your output for years, how can a typical user trust that you’ve not miscoded your algorithms? Imagine if ‘Rolls Royce’ was misspelt on all of their cars and turbo fans.
Meta-Analysis
The ubiquitous definition of min.entropy is:- $$ H_{\infty} = -\log_2(p_{max}) $$ But that’s not quite the whole picture. Determination of the apparently simple $p_{max}$ is not straightforward, as all these algorithms used to calculate it attest. And not forgetting the 26 pages of 800-90B dedicated to measuring non-IID $H_{\infty}$ and justifying themselves.
The issue is confounded by ea_non_iid reporting entropy in various units like 1 bit, 7 bit and 8 bit, yet entropic signals are typically consumed in octets, so how are 7 bit packets of entropy to be managed or extracted from? As:-
Compression Test Estimate (bit string) = 0.511761 / 1 bit(s)
Collision Test Estimate = 0.062150 / 1 bit(s)
T-Tuple Test Estimate = 0.028690 / 7 bit(s)
T-Tuple Test Estimate = 0.023100 / 8 bit(s)
Even with what we have, global confidence bounds are pretty relaxed leading to uncertainty as to the efficacy of these algorithms, compressive or otherwise, and thus to accurately measuring general min.entropy.
Must watch: Things become much clearer (but more worrisome) if the reader watches John Kelsey and Kerry McKay’s presentations at the NIST Random Bit Generation Workshop 2016, Day 1, Parts 1 & 2. Not the slides themselves, but the unguarded comments the presenters make. A précis:-
The new 2016 confidence criterion (p = 0.001) only applies independently to each specific test and predictor. It is not an aggregate universal bound on $H_{\infty}$.
Predictors are based on Shannon’s 1950’s work. Of seven decades ago.
ea_non_iid has features to detect limited local failures in the source signal via ’local’ predictors. These conflict with non uniform distributions such as Gaussian.
ea_non_iid has been tested on real world non uniform distributions. However “We don’t know what the answers should have been” - Kerry McKay.
There are elements of health checking and source failure compensation, diluting the purpose of the tool. “Jack of all..?”
Conclusion
“Estimating the entropy is non-trivial in the presence of complex and long range correlations.”
-Thomas Schürmann and Peter Grassberger.
NIST has been struggling for a long time to measure randomness.
It’s an impossible thing to do.
-John Kelsey, NIST.
Unfortunately then, $ H_{\infty} = -\log_2(p_{max})$ is not all it’s cracked up to be. The ease of determining $p_{max}$ in the IID case sadly does not extend to the non-IID case. What does min.entropy even mean in the general case given that correlated data is the superset of IID data with respect to an autocorrelation parameter? Most common bit, nibble, byte or tuple? And which tuples in what combinations? And what is their cardinality for data sets like the works of Shakespeare or JPEG files?
Babylon 5 fans will be familiar with Kosh, The Vorlon Ambassador. He said “The truth points to itself”. This is Aristotle’s concept of the scientific method in that what is true can be arrived at via many different and independent routes. Each one confirms said truth. With non-IID data sets though, we only have one path to follow (800-90B’s ea_non_iid program). There are many paths on the map, but only NIST’s is commonly promoted. How can 3rd parties independently verify the measurements then?
This all leads to ostensibly the greatest of mysteries in cryptography:-
$$ X = \frac{H_{\infty}}{H_{Shannon}} , Y = \frac{H_{Actual}}{H_{Estimate}} $$
Just what are $X$ and $Y$ numerically? A question perhaps even harder than the $P \enspace \text{versus} \enspace NP$ debate as most scientists have already coalesced around $P \ne NP$. $X$ and $Y$ remain unknown and open questions other than $X,Y < 1$ . Yet so many entropy measurement algorithms are founded upon compressive techniques. DIY entropy source makers should take heed, stay well away and decorrelate instead.
So therefore we conclude that for entropy measurement of real world (autocorrelated) sources, NIST 800-90B ea_non_iid is still pretty much:-
Notes:-
[†] Which is also an autocorrelation of 10% in terms of bitwise entropy shmear. I.e.
This gives an entropy shmear, $ES = \frac{6.02 - 5.40}{6.02} = 0.103$, or $\approx 10 \%$, where the compression file overhead ($k$) in using cmix v17 to compress a $10^6$ byte file = 66 bytes.